previous next
previous next 
PROJECT BAR-B-Q 2017
| home previous next |
|
| The Twenty-second Annual Interactive Audio Conference PROJECT BAR-B-Q 2017 |
 |
Group Report: CAAML: Creative Audio Applications of Machine Learning |
| Participants: A.K.A. "Pigmoid and the Funky Softmaxes" | |||||||||||||
| Marcus Altman, Dolby | TVB Subbu, Analog Devices | ||||||||||||
| Chris Bauerlein, Magic Leap | Alex Westner, Cakewalk | ||||||||||||
| Yipeng Liu, Cadence | Owen Vallis, Kadenze | ||||||||||||
| Konstantin Merkher, CEVA DSP | Anatoly Savchenkov, Synopsys | ||||||||||||
| Avi Keren, DSP Group | Michael Vulikh, P Product | ||||||||||||
| Adeel Aslam, Intel | Elia Shenberger, Waves | ||||||||||||
| Matthew Altman, DTS/Xperi | |||||||||||||
| Facilitator: Aaron Higgins | |||||||||||||
Problem Statement In recent years, machine learning has provided a number of state of the art solutions for computer vision1, text translation2, speech recognition3, and a host of other problems. It is clear that machine learning is a powerful tool for solving a wide number of problems, and that it has the potential to provide new solutions for audio applications. However, many of these audio applications have existing classical solutions or have latency and compute constraints that severely limit the use of the deeper neural networks. What is the set of audio problems that are amenable to machine learning? What is the set of audio problems for which classical solutions exist and are sufficient? What problems would benefit from a mix of classical solutions and machine learning? And finally, are there limitations or constraints that would exclude the use of a machine learning approach to the problem? A brief statement of the group’s solutions to those problems Many of the use cases discussed by the group already have classical solutions that solve the problems, and it was unclear what additional benefit would be gained by replacing these existing solutions with a machine learning approach. Additionally, many of the audio applications have latency or compute constraints that make it difficult or impossible to use the larger state of the art machine learning networks. It quickly became clear that machine learning is a powerful tool but not a panacea for all audio applications. However, further discussions revealed many opportunities where hybrid systems can utilize classical solutions and machine learning to improve existing audio applications. We have categorized examples of machine learning to better understand these opportunities. There are three categories based on the use of machine learning within an application: machine learning as a partial solution within a larger pipeline, machine learning as a full solution that stands by itself, and the use of machine learning in parallel with a classical solution. Additionally, we split the groups further based on whether the solution was an improvement to an existing application, or whether it was solving a new problem. Definitions
Example Details
Auto-generated subtitles
Self-driving cars: Audio sensors for safety, also multi-modal
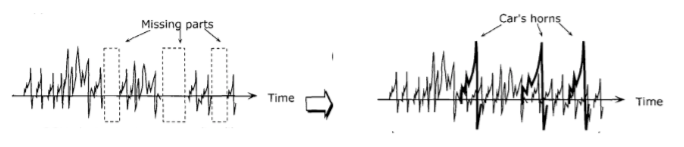
Audio Restoration
Double-Talk Detector
Anomaly Detection
Brainstorm of Audio Applications for Machine Learning & Artificial Intelligence Voice User Interface
Context awareness
Music synthesis (creating audio)
User experience
Conclusion Other reference material: There are also a number of creative tools that are emerging as well. Some examples are:
1 (2015, December 8). [1512.02325] SSD: Single Shot MultiBox Detector - arXiv. Retrieved December 1, 2017, from https://arxiv.org/abs/1512.02325 2 (2016, September 26). Google's Neural Machine Translation System: Bridging the Gap .... Retrieved December 1, 2017, from https://arxiv.org/abs/1609.08144 3 (2017, July 24). Exploring Neural Transducers for End-to-End Speech Recognition. Retrieved December 1, 2017, from https://arxiv.org/abs/1707.07413 4 (2016, August 9). Image Completion with Deep Learning in TensorFlow - Brandon Amos. Retrieved December 1, 2017, from http://bamos.github.io/2016/08/09/deep-completion/ 5 (n.d.). Deep Image Inpainting - CS231n. Retrieved December 1, 2017, from http://cs231n.stanford.edu/reports/2017/pdfs/328.pdf 6 (2015, July 31). Image Super-Resolution Using Deep Convolutional Networks - arXiv. Retrieved December 1, 2017, from https://arxiv.org/pdf/1501.00092
|
|||||||||||||
Copyright 2000-2017, Fat Labs, Inc., ALL RIGHTS RESERVED |