previous
previous
PROJECT BAR-B-Q 2007
| The Twelfth Annual Interactive
Music Conference PROJECT BAR-B-Q 2007 |
|
 |
Group Report: Overcoming Roadblocks in the Quest for Interactive Audio |
| Participants: | |
Charles Robinson, Dolby Labs |
Jocelyn Daoust, Ubisoft |
| Stephen Kay, Karma Lab | Karen Collins, University of Waterloo |
Nicholas Duveau, Ubisoft |
Barry Threw |
| Guy Whitmore, Microsoft | Tracy Bush , NC Soft |
| Jennifer Lewis, Relic | Kurt Larson, Slipgate Ironworks |
| Simon Ashby, AudioKinetic | Scott Snyder, The Edge of Reality |
Tom White, MIDI Manufacturers Association |
Facilitator: Aaron Higgins, Facilitator |
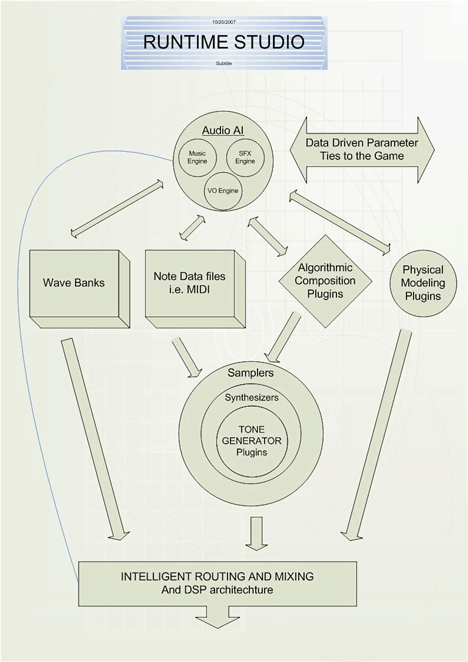
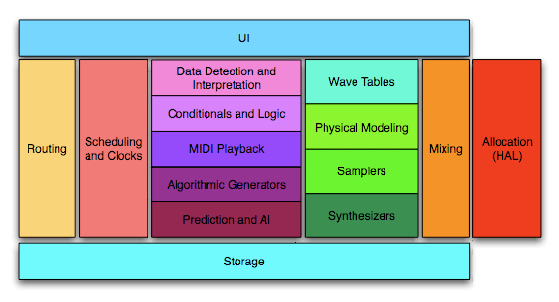
Currently, game audio often does not provide a highly variable, emotionally charged experience that is context-driven and sufficiently integrated into the game... There was a time when the idea of richly interactive audio was just a flicker in the minds of the gaming community. Visionary composers, sound designers, game designers and players dreamt of a time when the score of an interactive media work could be intimately intertwined with the user’s experience in an endearing and engaging way. Through experiment, innovation and sheer creative will these pioneers lit a path through the dark void of repetition and stasis; they overcame restrictive hardware, non-existent standards, poor funding and a lack of compositional tools to carry the torch forth into this new frontier. We have built frameworks and tools, we have composed breathtaking original works, we have agreed upon standards – indeed, we have come far toward the realization of our dream. It is a good time to look back and feel amazed at the long road we have traveled, but also a good time to look around to ascertain where we are. When we survey the landscape of game audio today what we find is that audio for interactive entertainment and games isn’t taking full advantage of the creative potential offered by the available platforms and hardware. We find many game scores that are only loosely tied to the actions and situations on screen rather than tightly integrated with game-play. We find repetition, we find stasis. With play lengths approaching epoch time spans, and plot lines becoming ever more open-ended it is more important than ever to encourage dynamic interactivity in our game audio. We feel that supporting our games with highly adaptive scores would increase the depth of a game’s immersion, widen the range (and increase the appropriateness) of a game’s emotions, and could help drive the game-play itself. With the dream of our forerunners held firmly in mind we have identified the largest obstacles blocking our progress and illuminated some possible paths around them. It is our hope that this will reignite efforts to pursue the highly elusive interactive audio score. The Problems Game audio has made some large strides in the past decade and a half, but our priorities have diverged from rich interactivity. Specifically, the production values of the audio assets themselves have improved dramatically. This was made possible by CD, DVD and HDD streaming capabilities, more available memory, and faster processor speeds. Gone is the (however comforting) 8bit audio of old, while the full production capabilities used to create film scores are being brought to bear on game audio; including live orchestras, high end studios, and the best DAW hardware, software and DSP. However, game audio has lost something important in this quest for fidelity; adaptability. When it comes to context-driven interactive audio, we’ve actually taken some steps backwards in our drive towards pristine audio assets. Many in our group pine for days past when music could be controlled at the instrument, note, or phrase level, rather than just by the three-to-five minute cue. In recent years sound designers and composers have had to compromise interactivity for the sake of the perceived quality of individual assets, both because of insufficient platform capability and limited funding. This bias toward audio resolution was actually the will of many composer/sound designers, the demand of our producers, and the wish of the people who play our games. But now in 2008, the trade-off of tight audio integration for high asset fidelity is no longer necessary. From the late 1990s through to the early 2000s, game platforms, game PCs, and audio tools were in a state in which it was difficult to have your cake (high production values) and eat it too (high interactivity). But, PCs and game consoles have evolved to the point where the needed power is under the hood to both support the highest quality assets and the most dynamic gameplay integration. Therefore our message to the industry is ‘no more excuses’! We have noticed many factors impeding the advance of rich interactive in game audio. Lack of will in content creators. There are many composer/sound designers who love creating and integrating audio content for games, and will go the extra mile to make it work well in context. But even for this dedicated group, creating adaptive content is a difficult slog; from convincing management of an idea, to working within a suboptimal production pipeline. And let’s face it, there are many in our profession who don’t want to do more than throw audio over the fence to a developer. New paradigms of audio creation are just emerging and most don’t want to jump on until those paradigms are established, it becomes more efficient to produce, and there’s money to be made! Lack of intuitive and comprehensive compositional tools. Game audio tools have also made tremendous strides in recent years. We may be on the cusp of a golden era of game audio tools, and so much of what we need is already available in third party audio engines, as well as some proprietary solutions. Even so, there are engine features the group defined that aren’t available in these engines (to be discussed later), and many audio designers/composers don’t take full advantage of the features that are there for various reasons. The foundations for the necessary composition technologies have been developed, but a full integration of all the disparate parts has not been achieved. Lack of interest by game producers and purse holders. In addition to technological issues, the group also pointed out problems with convincing management of the benefits of more adaptive game scores. Many purse-holders are reluctant to invest in new concepts and technology if they don’t see the immediate monetary value, i.e. “How many more units will this sell?” Without the ability to quantify the value of adaptive audio, many companies fail to recognize the difference that emotionally effective adaptive audio can have on the impact and enjoyment of their game. Some Solutions To little surprise, the problems presented are deep and have many facets, any specific portion of which deserves a dedicated working group. We discussed many areas at a high level such as tools, education, prototyping, various interactive audio techniques, game genres and their specific needs, and the anatomy of an audio system. However, our most promising direction lies in two parts, tool building and education. First, we define and refine the various components of an interactive audio system to reveal the underpinnings and potential of such a system. Second, we take steps to foster a forum and community of audio professionals in which case studies can be shared, and conversation and discussion encouraged. These things we hope will accelerate the evolution and adoption of advanced interactive audio techniques and greater range of expression within this fledgling medium. As part of the initial discussions, Guy Whitmore diagrammed the potential components and data-flow of a runtime interactive audio system (Figure A). In the vast majority of today’s systems, the only components are the Audio AI fed by calls from the game, Wave banks, and the mixing routing section. In the 80s and 90s (and currently on handheld devices, phones, and the Wii) systems commonly used MIDI data with wave-table synthesis. There’s a basic principle that the more granular your content, the higher the potential for adaptability. For example, music broken into 4-measure phrases (as waves) is more granular than a continuous 5-minute cue (wave), and music in the MIDI format is granular to the note and instrument level, and therefore has much more potential for adaptability. The first question addressing is what features our ideal system would contain. Our workgroup spent a great deal of time discussing what functionality we would like to see in an interactive audio system, and delineating this features greatly informed our direction of progress. However, the question of a minimal set of requirements in terms of allocation and resources still remained. A post-workgroup survey of composers by Kurt Larson shed some light on what the least amount of resources required would be (Appendix C). We decided to focus our limited time on what we dubbed the Audio AI portion of the system, as this is sort of the ‘conductor’ and coordinator for the other components. In the simplest terms, the Audio AI receives data calls from the game engine and decides what to do with that data. The most common and basic of these is a cue call (e.g. ‘wood door opens’), and the Audio AI determines the proper cue to play, which then triggers an associated wave file. Although the scope of what the Audio AI engine includes is a bit amorphous, we define it primarily as an information, as opposed to audio, processing entity. The Audio AI Engine, like any artificial intelligence or expert system, is a complex entity that requires a broad range of functionality to work correctly. Although much of this functionality has been achieved in disparate projects, the integration of them in an intuitive and robust way has not yet been achieved. While the task of creating an endearing and musical computer system is a seemingly opaque and insurmountable problem, a breakdown of the potential components will serve the ongoing discussion and development of adaptive audio. While details of implementation are largely outside the scope of this document, the following suggestions of modular components are informed by the desired abilities of the system, and by experiments with prototype systems (Figure 2). Routing, allocation, and scheduling The routing system is the interface from the Game Engine to all other components to the Audio AI system, and the interface of the system components to each other. As the point of entry for data from the Game Engine, it is responsible for querying, polling, or updating information on the game state. It also reports information about the audio state to the game engine. It is responsible for the passing of messages, control data, or audio data, between other system components. To address these tasks the Routing system must have knowledge of all components and parameters in the game, which necessitates a reporting scheme to delineate the available parameters. Keeping all data routed through a central authority in this manner has the advantages of creating a situation for mass storage of all parameters. This component also provides a hardware abstraction layer, to ideally keep compositions transportable across platforms. The allocation system would keep track of the necessary system specific resources to reproduce the audio, and assign these resources where they are most needed. This would also allow a composition to be scalable to less powerful systems, as the piece would be automatically conformed to available memory, storage, and voices. Additionally this foundation level would contain a clocking system to keep all system events in sync. Control, event and audio rate clocks should be present to allow for consistent timing of all game state information. Conditionals and logic While seemingly simple, a system for creating and nesting "if-then" and "and, or, not" types of statements and making decisions based on them allows for a very complex set of interactions. A system such as this should allow arbitrary chaining and nesting of logic groups. All parameters of game and audio engine state should be available for decision making, and for action once a decision has been made. Algorithmic processes Algorithmic generations would create streams of audio or control information that could be used for decisions, note generation, or mixing. Processes such as random generators, fractals, attractors, Markov chains, flocking simulators, particle generators or physicals models could generate a wide range of different input data and help fend off pure repetition in compositional sequences. Detection and information retrieval With such a huge range of data available to the system, it is helpful to interpret sets of data to make smarter decisions based on meta data. Components such as beat tracking, phrase matching, pitch matching, and harmony and key matching can be useful compositionally to make decisions based on current and prior musical results. Prediction The most difficult of components, the system should have the ability to intelligently interpret data on its own based on previous compositional structure and current data. Systems such as neural nets and fuzzy logic systems can be trained over the course of a game to make decisions that keep the musical material vibrant over the course of a many hour game. If built correctly these systems could also add indeterminate but intelligent aspects to the composition without having to specify every interaction in a decision or logic tree. UI and storage An intuitive way to author to all of these components, save the composition, and reload it on any conforming implementation in the future is necessary to give a system such as this a long life, and to allow compositions to retain their integrity over time. Having made some progress in terms of the compositional tools problem, we turned our focus toward the issue of composer and producer education. We resolved to use an approach from a previous Bar-B-Q workgroup, the Adaptive Audio Now initiative to set up a web presence to create a space to collect and aggregate interactive audio case-studies, post mortems, blogs, and other articles. This site will be set up to encourage dialogue and community among audio professionals and over time the number of articles will grow until the site becomes a invaluable destination for those looking to learn about interactive audio. Its home can currently be found at http://www.iasig.org/wiki/index.php?title=Adaptive_Audio_Now%21_Case_Studies. To help get the site content ball rolling we created two case studies, Appendices A and B. The philosophy here is one of emergence. That is, the evolution of game audio will largely come from the bottom up, rather than the top down. ‘Bottom up’ in this context refers to thousands of composers and sound designers who will experiment with ways of implementing adaptive audio, with the most successful techniques surviving and being elaborated upon. ‘Top down’ would be a group (like this work group) deciding what functionality future game audio systems would use and pushing those ideas on the industry. The Audio AI web presence is meant to foster and facilitate a natural bottom up approach, with the goal of improving game audio, its tools, and the environment we work in. Having defined our optimal tools, and created a forum for further discussion on the issues at hand, we feel we have made good first steps toward the furthering of our goals. Certainly many of the issues we have outlined need to be covered more in depth by additional workgroups and organizations. However, outlining our obstacles is the first step in toward overcoming them, and we now feel the path ahead is shown with much greater clarity.
The next step of the process is to create potential adaptive audio solutions based on the following scenario, both creative and technical. The frame: We’re in a video game, in an active village. One character approaches and passes another. They are cowboys. One is the player, the other a non-player character, an NPC. There is a third non-player character which may enter the scenario, the sheriff. Also known: There is music playing. One or more audio streams with multiple chords and key changes. There are 4 scenarios. #1 – the player walks past the NPC. No interaction occurs. On approach, pass by and away, we would however like to play a theme for that character, over top of the existing music. In time, with a specific instrument assigned to the NPC’s personality (as it’s an important part of the story). However, there are other times when the theme needs to play differently for varied contexts. The theme must be variable (respond to control sources) but always fit in perfectly with whatever music happens to be playing at the moment. #2 - the PLAYER decides to turn and Unholster their weapon. The NPC draws its weapon too. Crows stop cawing the towns folk stop chatting. The town quiets. Overall, the microphone goes to shotgun mode and all other sounds but that of the player and NPC come into extreme focus. #3 – REWIND: the PLAYER decides to turn and Unholster their weapon. The NPC draws its weapon too. The same music effects occur as above but with variation, as the sound engine is aware that this has occurred before. Still minor and still tense. #4 – REWIND AGAIN: the PLAYER AND NPC have weapons drawn. This time the PLAYER shoots and a fire fight begins. Tension mode is immediately transitioned into combat. The tempo jumps up naturally, different instruments and tracks come and go, perhaps the key changes. The arrangement re-arranges itself. As events happen in the fire fight, say for example each time the player fires a bullet, a trail of musically correct notes is triggered in an ascending sequence.
This is a description of the main forms of audio interactivity we should reasonably expect to see in a current-generation massively-multiplayer game. It provides accounts of a single player's experiences and how the audio interactivity supports those experiences. A case is made that live-rendered music will serve the needs of the game better than pre-recorded music. Our player logs in to her favorite massively-multiplayer game. There is some musical support for the game intro and character select screen, but the in-game music will be the focus of this study. She selects her favorite avatar named "Thalya". Thalya emerges into the game world inside her own private house. She walks over to her in-home music-playing system and turns it on. Music from places in the world to which she has been begins to play in a non-interactive form. She switches to another track she likes more. After a few minutes, she leaves the house, leaving the home-music system playing. As she emerges into the game world outside her home, the in-home music fades out. A streamed track of outdoor ambience sounds plays, and also, some 3-D-positioned sound emitters add more to that track. After a few moments, the game world music begins. - Pitch Our player reaches the central market square of the town. Since this is a special location, the world music fades out slowly and is replaced by a specific-location theme for the market. This music is more linear and traditional in its structure. The market music represents the culture of the inhabitants of the town. (This is especially important in a game which represents multiple cultures in different locations.) The background SFX track is replaced by a new one representing the sounds of the market: People talking, vehicles traveling by, birds, other animals, children playing, etc. On top of the streamed SFX track, 3-D-positioned sounds emanate from a handful of specific locations to provide a more immersive experience. Thalya conducts her business in the market. She buys things from NPC merchants, meets up (physically) with a few friends doing the same, and chats with friends both near and far. After about 5 minutes have passed, the market music has concluded. Rather than repeat, the market music concludes. For the remainder of her stay in the market, no music is heard, allowing Thalya to experience the sounds of the market itself. Finally Thalya and the three friends she met in the market decide to travel to another city to obtain a quest. They head off to the north. As they leave the market, the world music slowly returns, as does the default SFX background for the town area. As they get to the outskirts of town, they set off over late-summer wheat fields towards a distant forest. Once they are a hundred meters outside the city, the world music and the ambient SFX change to an entirely new set of assets. The SFX track crossfades seamlessly without a gap. Shortly thereafter, new 3-D positioned sound emitters add immersion to the wheat-fields, just like in the town. The music, however, fades out before reaching the SFX transition point. There is a 50-meter gap between the end of one music set and the beginning of another. (Alternately, there could be a much larger gap, so that a longer break from the world music is experienced.) The group enters the new music zone and the new music assets begin to be rendered to them. Although equally pleasant-sounding, the wheat-fields music sounds more open and free-form, representing the spacious feel of the area, as opposed to the densely-populated town. After a time of walking towards the distant forest, Thalya notices an easily defeat-able enemy ("mob", short for "mobile object") a few dozen meters off the path. Since she knows this particular creature often produces a valuable item as loot, she casually tosses a fireball spell at it, and it politely keels over and dies. The music and background sounds do not respond in any way. Why? Because the music of this game, unlike a movie, is not telling Thalya how to feel. It is attempting to intelligently support how we expect that she WILL feel. Although she technically engaged in "combat", we as composers and game designers know that she did not experience any serious threat or excitement. This was a casual kill done speculatively in the hopes of a minor reward. The music system does, however, make note of the fact that she has engaged in a minimal level of combat. More on that soon. Along the way, one of Thalya's friends needs to take a phone call in real life. (IRL!) He could set his character to auto-follow Thalya, but that is somewhat unreliable, so the group decides to stop and chat for a while during his absence. Combined with the somewhat-long walking time through the wheat-fields area, our group is now spending a significant amount of time listening to the same music. Luckily for them, the audio designers and composers of this game were well-versed in the needs of MMO game audio. The music is being live-rendered on the fly, and so never repeats. It always sounds consistently of the area's look and feel, but never do the players minds experience that little warning that says "All of this has happened before, and it is happening again!" regarding the music. Thalya's friend returns, and our group heads on towards the not-so-distant forest. They are not attacked by any of the roving potential enemies because our game system classifies these player-characters as too high-level to be attacked by enemies of the relatively low level found in the wheat fields. Since the players refrain from engaging them in combat, as they are intent on reaching their destination, the music continues in the same state, as do the ambient SFX. As the group approaches the forest, at about 200 meters out, the music fades out to silence. Upon running under the first trees, the background sounds change to forest sounds. Again, there is a streamed track and also 3-D-positioned sounds to supplement it. After about 100 meters, the forest music begins to gradually take form. Like the town music and wheat fields music, it is live-rendered and randomized to avoid repetition. Again, individual sounds are played, rather than entire pieces of pre-recorded music. In the forest, somewhat higher-level enemies abound. Some attack the group. Together, the group is vastly more powerful than their adversaries, and so the enemies are dispatched with minimal effort. The game's music AI system keeps track of their combat encounters. Every time the group engages an enemy, each player's combat tally is raised. The amount raised depends on the toughness of the enemy. For example, a single player engaging an enemy of the same level as the player will increase the tally by one. An enemy 5 levels above the player may raise that tally by two or more. Every few minutes or so, that tally is decreased by one. If the tally reaches a high-enough number, (that number being authored by the game's music director) the music begins to respond. Since at this point, our group's combat-tally number is fairly low, we do not expect that our players are in grave danger, but rather are simply eliminating enemies who briefly stand in their way. Therefore we only alter the music to a small degree. We increase the tempo a bit. A new part is brought in, high-pitched and strident, but quietly triumphant. Our group is merely doing what is needed to get to their destination, and the music acknowledges merely that they are taking care of business. Towards the other side of the forest, the enemies thin out, and the group goes for several minutes without killing an enemy. Their combat-tally number drops below the threshold and the music returns to its default state. Again, about 200 meters before reaching the outer edge of the forest area, the music fades to silence.
60 composers were asked what they felt would be the minimum resources required in a live-rendered, "GigaStudio-In-A-Box" system built into a gaming machine such that they could compose music which sounded not identical to, but AS GOOD AS fully-mixed dead streams. About 20 responded. Here is a summary of their responses: There was a strong response for the following: Also mentioned:
IASIG Interactive XMF Workgroup (IXWG) Bar-B-Q 2006 Group Report: Providing a High Level of Mixing Aesthetics in Interactive Audio and Games Bar-B-Q 2005 Group Report: New Approaches for Developing Interactive Audio Production Systems section 6 |
|
|
Copyright 2000-2014, Fat Labs, Inc., ALL RIGHTS RESERVED |