previous next
previous next 
PROJECT BAR-B-Q 2018
| home previous next |
|
| The Twenty-third Annual Interactive Audio Conference PROJECT BAR-B-Q 2018 |
 |
Group Report: |
| Participants: A.K.A. "Frankensynth and the machines" | |
| Jean-Marc Jot, Magic Leap | Rhonda Wilson, Dolby Labs |
| Rick Cohen, Qubiq | Dave Hodder, Novation |
| Howard Brown, Owl Labs | Lior Maimon, Waves |
| Francis Preve, Symplesound | Jon Bailey, iZotope |
| Martin Puryear, Google | |
| Facilitator: Aaron Higgins, 1010Music | |
Problem Statement Machine learning represents a huge opportunity. How do we explore this in the context of synthesis? Executive Summary During Project BBQ 2018, we explored potential applications of Deep Learning for audio synthesis, focused primarily on musical and mixed reality applications. Within this report, we explore potential synthesis use cases that could benefit from current approaches in Deep Learning, zeroing in on three specific examples Mixed Reality, Virtual Sound Designer and Unsupervised Waveform Synthesis and theorizing how those might be tackled with specific neural network architectures and data requirements. Terminology Synthesis (FP)
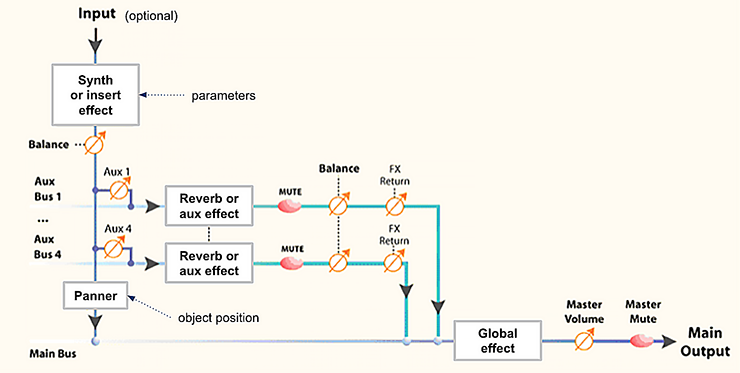
The above diagram illustrates a common mixing signal flow for music/movie production or games/VR/AR audio. Sound generation is performed in a first stage, including synthesis and optional insert effects, and produces a single or dual-channel audio signal. This signal is then subject to a spatialization process including spatial “panning” and artificial reverberation.
Machine learning / Deep Learning (RW) “Machine learning uses algorithms to parse data, learn from that data, and make informed decisions based on what it has learned.” “Deep learning is a subfield of machine learning. While both fall under the broad category of artificial intelligence, deep learning is what powers the most human-like artificial intelligence.” “A simple neural network is composed of an input layer, a single hidden layer, and an output layer. [https://www.quora.com/What-is-the-difference-between-neural-networks-and-deep-neural-networks] “Within the field of machine learning, there are two main types of tasks: supervised, and unsupervised. The main difference between the two types is that supervised learning is done using a ground truth, or in other words, we have prior knowledge of what the output values for our samples should be. Therefore, the goal of supervised learning is to learn a function that, given a sample of data and desired outputs, best approximates the relationship between input and output observable in the data. Unsupervised learning, on the other hand, does not have labeled outputs, so its goal is to infer the natural structure present within a set of data points.” [https://towardsdatascience.com/supervised-vs-unsupervised-learning-14f68e32ea8d ] “An autoencoder is a type of artificial neural network used to learn efficient data codings in an unsupervised manner. The aim of an autoencoder is to learn a representation (encoding) for a set of data, typically for dimensionality reduction.” A number of different networks/structures/architectures have been developed in deep learning. MLPs are suitable for classification prediction problems where inputs are assigned a class or label. They are also suitable for regression prediction problems where a real-valued quantity is predicted given a set of inputs. Batch normalization (BN) is a technique for improving the performance and stability of artificial neural networks. It is a technique to provide any layer in a neural network with inputs that are zero mean/unit variance. It is used to normalize the input layer by adjusting and scaling the activations. [https://en.wikipedia.org/wiki/Batch_normalization] The quantity and quality of the input data has a large impact on the performance of deep learning algorithms. Building the sufficiently large and relevant data set for a given application can take more time/work than building the network/architecture. Explored Use Cases As part of our discussions, we focused a conversation on use cases for either existing or (potentially) new forms audio synthesis that could benefit from approaches based on Deep Learning, resulting in the following list:
Use Case Focus To better explore the potentials for Deep Synthesis, we zeroed in a three use cases that broadly covered different creative domains (Music, Mixed Reality) and made use of different Deep Learning approaches (Supervised and Unsupervised learning). Use Case #1: Deep Synthesis for Mixed Reality The problem Synthesize “plausible” elementary sounds for virtual object interactions in VR or AR. Examples
Sample based approach Advances in computer-generated imagery have brought vivid, realistic animations to life, but the sounds associated with what we see simulated on screen, such as two objects colliding, are often recordings. Most sounds associated with animations rely on pre-recorded clips, which require vast manual effort to synchronize with the action on-screen. These clips are also restricted to noises that exist – they can’t predict anything new. Audio for virtual worlds is often generated using simple sample-based techniques. These leave much to be desired in terms of sound realism, especially where the sound is closely linked with visual cues. There has been much research into modeling natural sounds, but this has not yet developed into a comprehensive methodology for producing modeled audio content in virtual worlds. Physics engines are now routinely used to interactively simulate the motion of rigid bodies, deformable bodies, flexible surfaces and liquids. This sophistication only highlights the relative inadequacy of conventional audio techniques. Desired features, requirements
Physical modeling approach Wave-based Sound Synthesis for Computer Animation (Prof. Doug James, Stanford Univ., USA) SIGGRAPH 2018 “There’s been a Holy Grail in computing of being able to simulate reality for humans. We can animate scenes and render them visually with physics and computer graphics, but, as for sounds, they are usually made up.” “Currently there exists no way to generate realistic synchronized sounds for complex animated content, such as splashing water or colliding objects, automatically. This fills that void.” Informed by geometry and physical motion, the system figures out the vibrations of each object and how, like a loudspeaker, those vibrations excite sound waves. It computes the pressure waves cast off by rapidly moving and vibrating surfaces but does not replicate room acoustics. So, although it does not recreate the echoes in a grand cathedral, it can resolve detailed sounds from scenarios like a crashing cymbal, an upside-down bowl spinning to a stop, a glass filling up with water or a virtual character talking into a megaphone. The core of our approach is a sharp-interface finite-difference time-domain (FDTD) wavesolver, with a series of supporting algorithms to handle rapidly deforming and vibrating embedded interfaces arising in physics-based animation sound. Once the solver rasterizes these interfaces, it must evaluate acceleration boundary conditions (BCs) that involve model and phenomena-specific computations. We introduce acoustic shaders as a mechanism to abstract away these complexities, and describe a variety of implementations for computer animation: near-rigid objects with ringing and acceleration noise, deformable (finite element) models such as thin shells, bubble-based water, and virtual characters. Since time-domain wave synthesis is expensive, we only simulate pressure waves in a small region about each sound source, then estimate a far-field pressure signal. To further improve scalability beyond multi-threading, we propose a fully time-parallel sound synthesis method that is demonstrated on commodity cloud computing resources. Paper [high quality (98M)] [compressed (5.6M)] Supplemental Video [high quality (174M)] Advantages General approach. Supports a wide variety of physics-based simulation models and computer-animated phenomena. Highly detailed results. Perhaps the most significant improvements are in complex nonlinear phenomena, such as bubble-based water, where no prior methods can effectively resolve the complex acoustic emissions. Challenges Compute complexity. The most obvious limitation of our approach is that it is slow. Our CPU-based prototype allowed us to explore the numerical methods needed to support general animated phenomena, but the sound system “screams out” for GPU acceleration. Explicit physical models are often difficult to calibrate to a desired sound behaviour, although they are controlled directly by physical parameters Phya, physically based environmental sound synthesis (Dr Dylan Menzies, Univ. of Southampton, UK) 2011 Phya is a C++ library and set of tools for efficiently generating natural sounding collision sound within a virtual world. Sound types include impacts, scraping, dragging, rolling, and associated resonance of objects, solid and deformable. Loose or particulate surface sound like gravel, grass, foil can also be generated. Phya is designed to integrate with physics engines. There has been much research into modeling natural sounds, but this has not yet developed into a comprehensive methodology for producing modeled audio content in virtual worlds. Physics engines are now routinely used to interactively simulate the motion of rigid bodies, deformable bodies, flexible surfaces and liquids. This sophistication only highlights the relative inadequacy of conventional audio techniques. Features:
Lightweight C++ library and tools to facilitate the addition of modeled audio into virtual worlds, using a physics engine to provide macro-dynamic information about contacts and impacts. The project also includes an ongoing effort to develop audio models. The aim is to generate a practical, flexible and efficient system that can be adapted to a wide range of scenarios, while making consistent compromises. Once object audio properties and their links to physical objects are specified, the system can generate audio without further intervention. The properties describing the sound objects can be extracted from real recordings using analysis tools, a process sometimes called physical sampling. For instance a recording of an oil drum being hit can be analyzed, then used in a world where an oil drum was being rolled and hit. Instead of playing back that same sample again and again, we hear the variation in collision sound that matches its detailed motion. Another advantage, is that the memory footprint for the physical sample, is a small fraction of one short audio sample. Physical samples can also be edited in interesting ways not possible with direct samples.
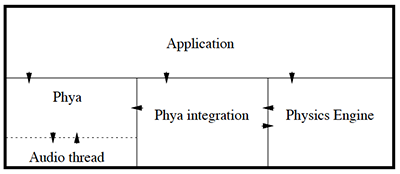
Components in a Phya application. Arrows point in the direction of function calls.
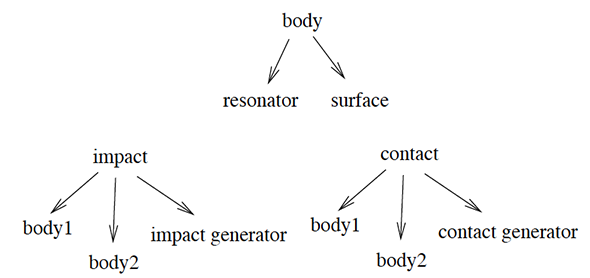
Main objects in Phya, with arrows pointing to referenced objects. Sound spatialization It is preferable to keep spatialization as separated as possible from sound generation, if possible. A large body of algorithms and software exist for spatializing, and the best approach depends on the context of the application. Output from Phya is available as a simple mono or stereo mix, or separately from each body so that external spatialization can be applied. Advantages Physical principles guide the system design, combined with judgments about what is perceptually A source can be given directionality by filtering the mono signal to produce a signal that varies with direction from the source. This technique is often used in computer games, and can be applied as part of the external spatialization process. Mono synthesis followed by external filtering can reproduce directional sound correctly, because at each frequency the directionality is fixed. For sources in general the directionality at each frequency can vary over time. Challenges Necessary to separate/categorize different types (“profiles”) of interaction and resonators . A machine learning approach? Existing work Speech synthesis using neural networks
A suggested direction Leverage the application of machine learning technique in the context of “traditional” synthesis techniques -- see below. Use Case #2: Deep Francis aka the Virtual Sound Designer This discussion imagined that we could train a neural network to replicate the facility of an experienced sound designer (Francis Preve) when recreating an existing sound via audio synthesis.
Possible Neural Network Architectures We imagine several different neural network architectures, relying on different input sources and producing different outputs, to build our Virtual Sound Designer.
We discovered that SAFE (Semantic Audio Feature Extraction) project can provide considerable insight for several of these concepts, as they are already extracting descriptor language from audio features. We also discussed the need the articulation data that generated the audio examples, so that we can feature extract temporal parameters. Data Needs What data do we need to gather, to seed the database? Here are some proposed requirements:
A hypothetical approach
Use Case #3: An Unsupervised Synthesis Approach
References Object collision sound modeling Music composition, synthesis Music audio classification https://towardsdatascience.com/the-promise-of-ai-in-audio-processing-a7e4996eb2ca Semantic audio Dylan Menzies, “Physically motivated environmental sound synthesis for virtual worlds.” EURASIP Journal on Audio, Speech, and Music Processing, 2010. pdf Dylan Menzies, “Phya and vfoley, physically motivated audio for virtual environments.” Audio Engineering Society Conference: 35th International Conference: Audio for Games. Audio Engineering Society, 2009. pdf Jui-Hsien Wang, Ante Qu Timothy R. Langlois, Doug L. James, “Wave-based Sound Synthesis for Computer Animation.” ACM SIGGRAPH, 2018. pdf Leon Fedden “Using AI to Defeat Software Synthesisers.” 2017
|
|
Copyright 2000-2018, Fat Labs, Inc., ALL RIGHTS RESERVED |