|
The voice-assistant experience has rapidly matured but there is still room for improvement. In the next 5 years, the expectation is that the customer experience will work seamlessly on more devices, in more environments and across multiple voice assistants and content agents in order to enable a more intuitive user experience. Currently, the various voice assistants (Alexa, Bixby, Cortana, Google Assistant, Siri, etc.) rarely are on the same device and and there is no mechanism to test them in an objective and repeatable fashion. Consumers want to access any service from any device at any time.
Define and benchmark from an OEM and consumer perspective the ideal voice assistant experience.
- Split evaluation process into different elements and define benchmarks for each.
Today’s devices support only their own branded service.
3rd party device makers want an OEM-branded voice interface with access to the various voice services for the optimized capabilities.
Monetization - Consumers may have a different agenda than the vendors. Not going to share NLU databases.
NLP is still customized to the skills and use cases from the assistant provider.
Can we have an architecture vision where the ASR and NLP all may reside closer to the end user (with a closer relationship to the user) with a standardized interface to multiple assistants. Gateway to everyone’s walled garden. Business implications may prevent this?
Standardized testing is in development, but the primary players aren’t in the standards committee at this time. Their direction may not be sufficient. Their may be practical drawbacks to address the needs of the community.
Need to expand testing for more use-case environment. Accurate testing requires more facilities and money.
Difficult to separate testing of the AFE, ASR, wake word from complete system testing.
Playback system testing (level, FR, THD, SER)
1: Consumer Experience
What do we want this to do in 5 years that it is not doing today?
- Reliable interaction with a voice assistant in any environment.
- Fair goal for 5 years is human level of listening.
- Voice assistants are integral as a phone in daily life
- Make voice the preferred method of communication with digital life (when appropriate)
- Define when voice is the most effective method of communication
- Discreet communication with your voice assistant (Sub-Ambient)
- Personal voice listening model makes communication more efficient
- Multiple wake-words on every device (technical / business limitations to overcome)
- User-defined keywords in addition to VA brand names? (how to test)
- Product-branded OEM keywords may not be too strong, but at least they can be tested.
- Want publicly-stated test statistics so consumers can make purchasing decisions ($ vs performance)
Vertical products
Smart speaker – indoor, outdoor, workshop, industrial (environmental buckets)
Personal devices
Automotive
Enterprise – conference room (quiet)
Industrial – factory (loud)
Point of Sale
Call center virtual assistant
Voice over IP
2: Technical metrics for evaluation and improvement
for ease of reading the keyword or wake word is simplified to “Alexa” for readability
Terminology and Acronyms:
AFE – Audio Front End (Noise suppression, to pull the speech out of the noisy / reverberant environment)
ASR – Automatic Speech Recognition (What words were said?)
NLP – Natural Language Processing (Determine the intent from the words said)
NLU - Natural Language Understanding
TTS - Text-To-Speech
DUT device under test
FRR wake word False Rejection Rate
The number of missed wake words per wake words spoken utterance
TPR – True positive rate (1 – FRR)
RAR – Response Accuracy Rate
The number of right responses per corresponding requests
WER – Word Error Rate
The number of incorrect words vs. expected or correct words
FAR - wake word False Alarm Rate
The number of unwanted wakes per a given period.
UPL – User Perceived Latency
The time from end of utterance to beginning of response from the device
WWDD – Wake Word Detection Delay
The minimum time that a particular device requires a user to pause between saying "Alexa" and the remaining request in order for the Alexa Voice Service to reliably receive the entire request.
Barge In – Ability to wake the device during device originated audio. (better definition)
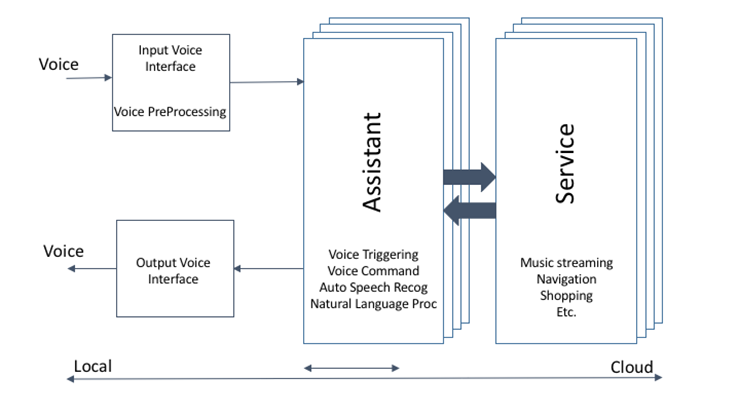
A: Front End Testing (Keyword and ASR)
Expand environmental test cases (farther talkers, more noises, noise types (stationary vs. non-stationary), and noise locations
Need constrained scoring tools (not affected by cloud-based learning)
Keyword simulation
B: System Testing & Benchmarking
If we pierce the walled-garden, system level testing is harder
Cannot test user-created keywords
Combine FAR and FRR into a single figure of metric for easier communication?
AFE Noise Suppression (signal to noise ratio improvement (SNRI)
To avoid too much increase of scale or equipment, elevation is being ignored with complete coverage. Device Under Test should be placed at
Current AFE testing for Voice Assistance is done through evaluating RAR. In the future, this should be done through a speech intelligibility metric like PESQ (Perceptual Evaluation of Speech Quality) for voice assistants.
Repeatability
A system or set of tools that enable a given set of tests run in the same conditions produce the same result with error.
To scale to enable multiple device makers and suppliers to develop products, the same condition apply to be able to have correlation between labs
Verticals and Use Cases
Smart Speaker
Automotive (ignored in this paper)
Wearables / Hearables
Metrics on these are environmentally dependent.
Product processing framework
Input PreProcessing - front end far-field capture
Noise suppression
Echo cancellation, barge in
Gain management
Wake word engine
Multiple triggers?
Automatic speech recognition
Natural Language processing
Convert words to intents and intents into tasks
Context retention
Post Processing/Rendering
Playback
Intelligibility
Turing test
Mechanical/Industrial Design
Acoustics (input and playback)
Specifications
Playback Processing and Performance:
The user experience and perception of overall product quality will be influenced by the quality of the playback loudspeaker signal. Appropriate tests and metrics need to be defined for the playback performance, including the classical measurements for the loudspeaker system and system-level playback features. These should at the minimum include:
Level: The speaker output level should achieve the levels required as bounded by the use case. Naturally, if the device is intended to be used farther away (larger room) or in a louder environment (kitchen, automobile), the product requirements specification should be adjusted accordingly.
Frequency Response: The frequency response should be reasonably flat measured across the specified audio range. The specified audio range is also determined by the use-case in the product specification as well (i.e. narrowband speech, wideband speech, music playback). Naturally, the low-frequency (bass) capability is limited by the product size and enclosure design. A good first-order frequency response test is to start with a single-point frequency response measurement at a primary use-case position in an anechoic chamber to verify the speaker is aligned with it’s enclosure well. Any tests done in a real room will have to be smoothed and averaged accordingly.
Directivity: The frequency response should not excessively deviate from the on-axis ideal at other listening angles, especially if the product is marketed as omnidirectional playback.
Total Harmonic Distortion: The classical measurement for Total Harmonic Distortion (THD) as well as higher-order “Rub & Buzz” measurements should be used to verify the quality of the loudspeaker transducer, enclosure, and assembly. Any non-linear THD due to the transducer behavior, mechanical rattling and buzzing of the chassis parts, or even turbulent port noise from a bass-reflex port will cause the product to sound bad and the Acoustic Echo Canceler (AEC) to fail. A poorly-performing AEC will prevent full-duplex voice conversations and ASR barge-in performance.
Linearity: It is common practice to use Dynamic Range Control (DRC) in the playback processing to increase the loudness of the playback signal to overcome deficiencies in linear playback headroom due to a small, inefficient speaker or perhaps voltage headroom on the amplifier rail. Consumer are more willing to accept the sound of DRC on small, handheld devices where hearing the speech on the small device is the priority. However, on a high-end music player, consumers will expect a more linear response with higher dynamic range.
Advanced Playback Features: If the product contains advanced playback signal processing features, such as room-compensation auto-eq, auto level normalization, playback beaming, etc. then appropriate tests will need to be defined and created for those features as well.
Speech to Echo Ratio (SER): A key metric in how well barge-in is going to work (for ASR) and full-duplex conversations (for voice calls) is the Speech to Echo Ratio of the device and how well the Acoustic Echo Canceler (AEC) can cope. The speech to echo ratio is the ratio of the signal level at the Device Under Test (DUT) microphones from a desired talker (at the use case-defined distance and level) to the energy at the DUT microphones from it’s own self-generated playback signal. Key design attributes that affect the SER are the speaker to microphone distance (as well as mechanical design), good internal seals and design to prevent internal (to the product chassis) echo leakage and vibration coupling, and the overall level of the playback signal itself. The measured SER can be used to predict full-duplex and barge-in performance, and minimums from known-good “golden” samples of the product can be used to determine the product’s design target and watch for assembly variations in production.
Intelligibility depends upon other processing in the system.
Benchmark the parts individually, then as a whole system.
What tests do we use to measure the terms above?
How do I create a common test set for all devices and give them an assistant based score? This is dependent on language due to proximity of keywords.
Learning engines (or software updates) will have different scores with each run.
Learning rates can really impact results. Can’t get fair and repeatable results.
-
Need to provide a fully pre-conditioned model with no additional learning to test, or fully reset account with no learning to measure learning ability.
Wake word vs. command processing needs to be different tests
What are the parameters of a guest speaker ID? Time constraints, voice pins expose weaknesses.
How do you transport voice accounts?
Need test protocol for biometrics to test speaker ID and transport methods.
Recertification needed per feature per product.
Do the acoustic tests represent real world use cases?
Working toward a set of benchmarks to qualify different systems.
Tests are practically constrained by cost of test systems (can get ridiculous)
Should we try to segregate the testing of the AFE from the full system (trigger and voice service)?
To accomplish this, what is the method to freeze the cloud component (ASR and NLP)
Multiple talker testing is for the Audio Front End (AFE)
Amazon environmental buckets:
Far field – at least 3 meters
Close Talk – within arms length
Automotive –
Do not want to get distracted by Security stuff
Comfort of getting info from voice service is more in the scope.
Push notifications are very interesting. Can be done right, can be intrusive.
Voice over IP, human voice communication is beyond the scope of this report.
There are no examples of playback testing (as opposed to Barge in testing)
Music, voice/speech.
Final OEMs make a lot of decisions beyond the scope that testing can protect.
Ducking can be jarring.
Normalization is a user specific quality. Should it be?
When other backend services fail, the front end (Alexa) is the target of the user’s angst
Preferences to allow pleasantries
Please and Thank You can be an application
Don’t be Clippy!
Should the speaker be proactive.
Push/proactive speaking needs to be non-startling
Push notifications need to understand context (don’t tell me the score of the game on my DVR)
What user experiences will 5 years of noise processing enhancement create?
What will local voice assistant architectures create for contained experiences?
Sound identification, classification will help us selectively suppress noise and enhance signal.
Biometric anti-spoofing will become more effective
Important things we didn’t work on (though we actually did):
Natural Language Processing is not conducive to benchmarking
Voice assistant is key to branding, and important to for product definition.
Setting up voice assistants in your oven is like the blinking clock on the VCR
How do voice assistants interact with each other.
How the AI interacts with the user is a crucial part of the product.
NLP Learns from you over time the level of personality comfort you want as a user.
There is a balance between security and convenience
We won’t be talking about:
5 years out, number of major ecosystems will drop to two-ish, and other services will be a skill for a specific purpose.
Specific Skills Testing
We want a “PESQ for Machines”
Dave Berol Notes from Tuesday, October 9th.
Useful Links:
Blog post on setting up a self test for Alexa:
https://developer.amazon.com/blogs/alexa/post/f7aad965-76f5-435f-86de-7861ece48709/how-to-create-a-self-test-room-and-evaluate-your-alexa-voice-service-integration
ETSI Workgroup topic
Title |
Speech and Multimedia Transmission Quality (STQ); Methods and procedures for evaluating performance of voice-controlled devices and functions: Voice assistants
Voice assistants |
Scope and Field
of Application |
To develop methodology for repeatable characterization of voice assistant devices and functions, including: input speech signals and geometric relations of talkers and devices; control of acoustic environment; control of background noise signals; response measures and their collection and statistical analyses. |
https://portal.etsi.org/webapp/WorkProgram/Report_WorkItem.asp?WKI_ID=51392
Benchmark as the solution versus audio front end alone; as well as test the total solution.
How do you perform testing of multi-agent devices?
- Need to create a baseline for each L wake-words.
- Confirm L recordings of wake word work in silence (noise floor of test room; non-anechoic) at nominal distance for each Voice Assistant.
- Confirm N recording of requests in silence (noise floor of test room; non-anechoic) at nominal distance.
- Wake word and request matrix should be from the same original user (voice actor)
- Reproduce WW + WWDD + M for each test condition. Loudness, WWDD, and background noise conditions are defined by a test set.
- Background Noise environment should be played for 30 seconds at the right level to avoid impact transient change (quiet to loud).
Other Reports:
A.K.A. "Always Listening, Always"
https://www.projectbarbq.com/reports/bbq17/bbq17r3.htm
"2016: A Voice Odyssey: I'm sorry, Dave. I'm afraid I can't do that...yet."
https://www.projectbarbq.com/reports/bbq16/bbq16r3.htm
A.K.A. "Audio Of Things"
https://www.projectbarbq.com/reports/bbq15/bbq15r4.htm
A.K.A. "Talk to the P.I.C.K.L.E. (Personal IoT Connected Knowledgeable Life Enhancement)"
https://www.projectbarbq.com/reports/bbq14/bbq14r7.htm
A.K.A. "Clothing Optional"
https://www.projectbarbq.com/reports/bbq12/bbq12r5.htm
END Dave Berol Notes from Tuesday.
Dave Berol Notes, Weds, 10/10
Cortana / Speech
WinHEC 2016
https://sec.ch9.ms/slides/winHEC/2_03_Cortana_Speech_Platform.pdf
ETSI EG 202 396-1 V1.2.2 (2008-09)
ETSI Guide Speech Processing, Transmission and Quality Aspects (STQ); Speech quality performance in the presence of background noise; Part 1: Background noise simulation technique and background noise database
https://www.etsi.org/deliver/etsi_eg/202300_202399/20239601/01.02.02_60/eg_20239601v010202p.pdf
Another approach to metrics would be to view on a receiver operating curve so you can define a rate or tuning to have a point of comparison.


Alexa Acoustic Testing Notes:
Terminology
Term Definition
request The portion of the utterance after the wake word.
Response
Accuracy Rate
(RAR)
The number of right responses per corresponding requests.
Wake Word False
Alarm Rate (FAR)
The number of unwanted wakes per a given period.
Wake Word False
Rejection Rate
(FRR)
The number of missed wake words per wake words spoken.
utterance An expression spoken to an Alexa-enabled device.
wake word The first word of the utterance, “Alexa”, which signals
section 4
|
 previous next
previous next 
