previous next
previous next 
PROJECT BAR-B-Q 2018
| home previous next |
|
| The Twenty-third Annual Interactive Audio Conference PROJECT BAR-B-Q 2018 |
 |
Group Report: Taking the virtual out of virtual audio |
| Participants: A.K.A. "Is it Enigma or is it Memorex?" | |
| Andie Ray, Dolby Laboratories | Phill Williams, Netflix |
| David Roach, Magic Leap | Mike Minnick, Magic Leap |
| Scott McNeese, Surfaceink | Martin Puryear, Google |
| Brett Patterson, Firelight Technologies Pty Ltd | |
|
Problem Statement
Most audio is hyper-real. Audio for games, TV and movies, goes beyond ‘realistic’ sound to suspend your disbelief and immerse you in an experience. Even meticulously-recorded music is mixed into a hyper-real presentation. As of today, audio attempting to be truly ‘real’ is limited to certain musical recordings and a handful of other stuff. AR experiences are currently a small but growing subset. Distractions are exponentially more difficult to deal with in AR, since both virtual video and virtual audio objects must be modeled accurately. It’s much more difficult to suspend disbelief when we are living in the real world. As AR/MR rises in popularity, is it now more important than ever before to be able to convey real audio. Hyper-real sounds pull you out of an augmented environment. But it is not sufficient to simply make binaural recordings of environments … the sound is interactive, and aspects have to be procedurally generated. So what is needed, and what are the obstacles? Obstacles
Out-of-scope topics for this paper
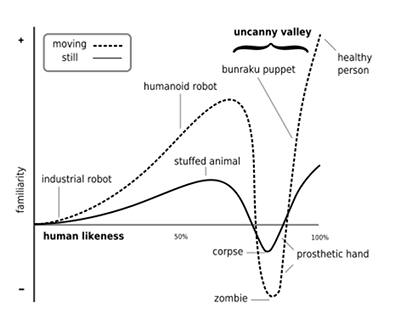
The uncanny valley of audio Uncanny Valley: the phenomenon whereby a computer-generated figure or humanoid robot bearing a near-identical resemblance to a human being arouses a sense of unease or revulsion in the person viewing it.
To date, there is a small amount of literature on the topic of an “aural” uncanny valley for audio. This will be an area of great interest, in the future, because for an audio presentation to be real, the uncanny valley must be avoided. While it is beyond the scope of this document to attempt to fully define the aural uncanny valley, here are some references: From The audio Uncanny Valley: Sound, fear and the horror game.:
Recommendations and observations Fidelity
Virtual objects must match the real world acoustics
The content must be balanced with the real world to be believable
The content must not sound arbitrarily generated (i.e., footsteps should vary and never repeat)
What is good enough to be believable?
Realness Subjective Tests Below are two examples of subjective test methods that may be useful to rate the realness of an M/AR audio system. They are presented as introductory ideas; other test methodologies may be equal to or better than these. Example of an attentive test of audio realness In front of the listener is an acoustically-transparent screen (or the subject is blindfolded). Behind the screen is an acoustic sound source. Also present is a playback system. During the test, either the acoustic source or the playback system plays a sound.
Questions What would the speaker-produced audio need to do?
Thoughts It is clear that if only pre-recorded or synthesized sounds are used, there would need to be a corpus of them to convey the variance expected of a natural sound. Perhaps one practical way to accomplish the test would be to procedurally generate the sounds. Parameters for a passive test of audio realness A measure of audio realness is the ability of the audio to contribute to an immersive experience without inadvertently breaking suspension of reality. A test of this attribute would necessarily be passive, as the audio must blend into the experience. This can help us quantify the threshold of believability.
References & Additional Reading The Bandwidth of Human Perception and its Implications for Pro Audio by Thomas Lund (AES Library) Carnegie Mellon: The challenges of testing in a non deterministic world Will Virtual Reality Get Lost in the Uncanny Valley Of Sound? Gamastura: Virtual Reality in the Uncanny Aural Valley Examples of ‘uncanny’ sounds generated by ML
|
|
Copyright 2000-2018, Fat Labs, Inc., ALL RIGHTS RESERVED |