previous next
previous next 
PROJECT BAR-B-Q 2019
| home previous next |
|
| The Twenty-fourth Annual Interactive Audio Conference PROJECT BAR-B-Q 2019 |
 |
Group Report: |
| Participants: A.K.A. "Not Hot Dog" | |
| Rick Cohen, Qubiq | TVB Subbu, Analog Devices |
| Scott McNeese, Surfaceink | Jonathan Bailey, iZotope |
| Craig Linssen, Apple | Larry Przywara, Cadence |
|
Brief statement of the problem(s) on which the group worked: All of us have had the experience of sitting down to watch a movie or other A/V content they craved only to have the experience degraded by audio rendering issues. Perhaps the dialogue is barely intelligible, the music soundtrack is overbearing, or the sound effects are lost due to a mismatch between encoding and decoding and or limitations of the acoustical playback system. Perhaps you forgot to change the audio settings on your device from “movies” to “music” before listening to your concert. How often has your immersion been shattered by a blaring commercial in the middle of a dramatic scene? Is machine learning a viable cure to these and other audio rendering issues? Can machine learning also make the experience more personalized to the user and optimized for the class of media? Can machine learning also address future home entertainment challenges as technology unlocks more interactive and immersive experiences? Expanded problem statement: The problem can be segmented as follows:
Expanded Solution Description Proposed Systems Architecture
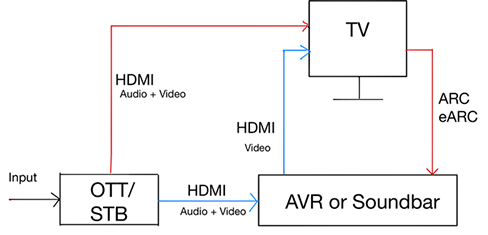
The block diagram above shows a typical home entertainment system. HDMI signals contain multiplexed video and audio content. Current TVs, AVRs, and Soundbars include a decoder for the HDMI signal. The decoder then passes the raw audio (and video) streams to rendering devices (downmixing to the actual number of speakers). The renderer is then connected to post-processing, which performs tasks such as selecting a soundfield mode, applying EQ, and similar functions. In our proposed architecture, a Machine Learning processor is inserted between the decoder + renderer and the post-processor. The ML processor analyzes the audio data, and creates control signals which can be used to manipulate the parameters of the post-processor. Renderers often contain proprietary algorithms, and so for practical reasons we cannot add Machine Learning into the path before the renderer. In an “open world”, this would allow for additional capabilities in the classification of the audio. See the “Proposed Neural Network Architecture” section of this report for information on how the ML device analyzes the audio data to create the control signals. Software Requirements There are 2 types of algorithms utilized in the ML processing. One is signal processing feature-extraction, filtering, transforms etc. The others are Neural Network based sound classification, context-understanding, etc. The 1st type utilizes 32-bit MAC fixed point and/or single precision floating point and the 2nd type utilizes NN MACs supporting 16x8, 8x8 or lower weight sizes. DSPs supporting a large number of 32-bit MACS, 16xN-bit MACs and multiple FP operations/cycles will provide the most energy and cost efficient solution. Machine Learning Terminology Machine learning / Deep Learning (RW)
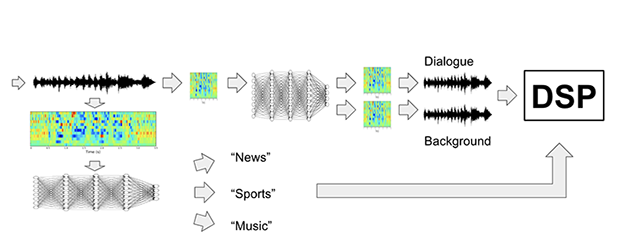
“Machine learning uses algorithms to parse data, learn from that data, and make informed decisions based on what it has learned.” “Deep learning structures algorithms in layers to create an “artificial neural network” that can learn and make intelligent decisions on its own.” “Deep learning is a subfield of machine learning. While both fall under the broad category of artificial intelligence, deep learning is what powers the most human-like artificial intelligence.” [https://www.zendesk.com/blog/machine-learning-and-deep-learning/] “A simple neural network is composed of an input layer, a single hidden layer, and an output layer. [https://www.quora.com/What-is-the-difference-between-neural-networks-and-deep-neural-networks] “Within the field of machine learning, there are two main types of tasks: supervised, and unsupervised. The main difference between the two types is that supervised learning is done using a ground truth, or in other words, we have prior knowledge of what the output values for our samples should be. Therefore, the goal of supervised learning is to learn a function that, given a sample of data and desired outputs, best approximates the relationship between input and output observable in the data. Unsupervised learning, on the other hand, does not have labeled outputs, so its goal is to infer the natural structure present within a set of data points.” Convolutional Neural Networks, or CNNs, were designed to map image data to an output variable. The CNN input is traditionally two-dimensional, a field or matrix, but can also be changed to be one-dimensional, allowing it to develop an internal representation of a one-dimensional sequence. Proposed Neural Network Architecture For much of the past decade, deep neural networks have offered solutions to the problems associated with inferring metadata from content, particularly image, video and audio. Frequently used for image “classification” (or labeling) and especially for facial recognition, the convolutional network network can be used to classify the audio stream and assign a label dependent on the content, such as “News” or “Sports,” etc. Once the system has assigned a label to the content stream, that information can be provided to the post-processing and/or rendering engines to select an appropriate audio preset or mode for the audio system, which will then process the audio appropriately based on the determined content type and output the processed audio via the users’ home entertainment system. A proposed block diagram for this use case is shown below. This block diagram begins once the audio has been decoded. That PCM stream of audio should be converted into a spectral representation and fed into a trained convolutional neural network, which will output a label. That label will be fed to the DSP system to set the appropriate preset or mode for audio processing and subsequent amplification.
In the future, we can contemplate additional options that can process the audio more surgically. Neural networks have also demonstrated their usefulness at unmixing audio using spectral masking. An enhanced neural network could make use of such an approach to, for example, separate the dialogue audio content from the rest of the sound effects, music, ambience and other background audio tracks, for separate processing. The diagram below demonstrates a potential systems architecture for such a system.
In this example the audio is labeled (“classified”) as before, but we have added an additional neural network that can perform a spectral masking step to “separate” the audio signals into dialogue and “background” (or all other) audio tracks for independent processing via the post processing and rendering systems. Personalization and Customization We imagine that, in addition to the pre-built processing (e.g. categorization/classification) performed by this system, there will be a number of user parameters which can be customized in order to fine tune the learning model. “Fine-tuning means taking some machine learning model that has already learned something before (i.e. been trained on some data) and then training that model (i.e. training it some more, possibly on different data). “ [https://www.quora.com/What-is-the-difference-between-transfer-learning-and-fine-tuning] Some simple examples:
These parameters could be directly set by the user, or learned by the system while observing the listening behavior of the user. The system could then feed back the user’s changes into the model, to improve the classifications. This is known as “on-line fine tuning”. “Preference learning is a subfield in machine learning, which is a classification method based on observed preference information [1]. In the view of supervised learning, preference learning trains on a set of items which have preferences toward labels or other items and predicts the preferences for all items.” [https://en.wikipedia.org/wiki/Preference_learning] The data set (source domain) of another prototypical user can also be adapted to the current user (target domain). This is called domain adaptation or transfer learning. “Domain adaptation[1][2] is a field associated with machine learning and transfer learning. This scenario arises when we aim at learning from a source data distribution a well performing model on a different (but related) target data distribution. For instance, one of the tasks of the common spam filtering problem consists in adapting a model from one user (the source distribution) to a new one who receives significantly different emails (the target distribution). Domain adaptation has also been shown to be beneficial for learning unrelated sources.[3] Note that, when more than one source distribution is available the problem is referred to as multi-source domain adaptation.[4]” [https://en.wikipedia.org/wiki/Domain_adaptation] One system might have a collection of separate users. For example, different family members or combinations of family members playing a game or watching a sporting event/concert/news on their entertainment system. Therefore the system could store a separate customization for each situation. This is known as Personalization. [https://digitalgrowthunleashed.com/the-future-of-personalization-with-ai-and-machine-learning/] What’s next?
Conclusions:
Inspiration / Links Machine learning for synthesis (Project Bar-B-Q 2018 report) https://valossa.com/
|
|
|
Copyright 2000-2019, Fat Labs, Inc., ALL RIGHTS RESERVED |